Here is how you can stop your Robots.txt files from being indexed
We have seen that a new website is a combination of various pages which can be a blog page, about us page, and various other pages. However, this is simple for us to navigate and I am talking about humans. This is definitely not easy to navigate for robots and for this reason, there was […]
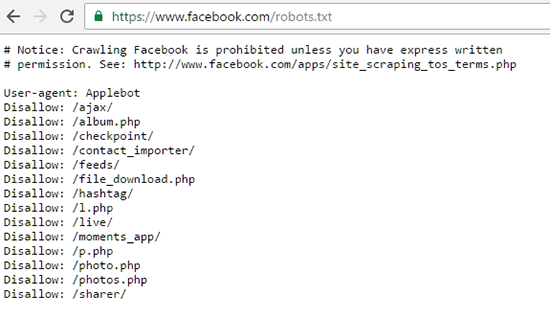
We have seen that a new website is a combination of various pages which can be a blog page, about us page, and various other pages. However, this is simple for us to navigate and I am talking about humans. This is definitely not easy to navigate for robots and for this reason, there was the need of robots.txt file and sitemaps. Basically, you are telling the robots in a robots.txt file that which page is located where on your website and which sites are needed to be indexed and not indexed.
However, the problem is that there are times when our robots.txt files are also indexed. Generally, there is no need to index the robots.txt file for any website as they are not useful for anyone to see. But the problem still occurs and we then need to de-index the file if needed or people just keep it as it is. While keeping it as it is not an issue, it is better to not index the robots.txt file in first place. So we now have advice from Google’s John Mueller on how to avoid indexing the robots.txt file for any website. He said that x-robots-tag HTTP header can be used to block indexing of robots.txt or sitemap files.
However, he also had some bad news for websites which had their robots.txt files indexed as he mentioned that “if your robots.txt or sitemap file is ranking for normal queries (not site:), that’s usually a sign that your site is really bad off and should be improved instead”. Google’s John Mueller revealed this when fellow Googler Gary Illyes revealed that there is no way to stop robots.txt file from indexing just like you would index normal URLs for your website. The key part about the statement from John is that if the robots.txt file is indexing, there is a problem which needs to be fixed.
More in How-To
View allSEO users and publishers facing indexing issues due to two outages as named by Google
Recently, it was seen that many of the users were experiencing some issues in Google. The representative of Google that is Danny Sullivan announced that two outages were responsible for the problems in Google Search. Among these two outages, the first one affects mobile indexing. The second outage i
Google was quick to solve indexing issue with news articles reported by some users recently!
Recently, Google went through an issue which made new articles appear in the section of Top Stories. People were quite shocked to see the new articles in the section of Top Stories of search results. The issue was registered on 11th September 2020. As per the reports, the issue started from 3 pm PT.
Bing launched new and improved Robots.txt tester tool for SEO publishers
Bing has announced a new tester tool, Robots.txt. The tester tool is very important and needed, as per the officials. If you get robots.txt wrong then it can result in very unexpected SEO outcome. Therefore, it is very important to create a perfect robots.txt file. This file is a top priority for Se