How To's
Here is how you can stop your Robots.txt files from being indexed
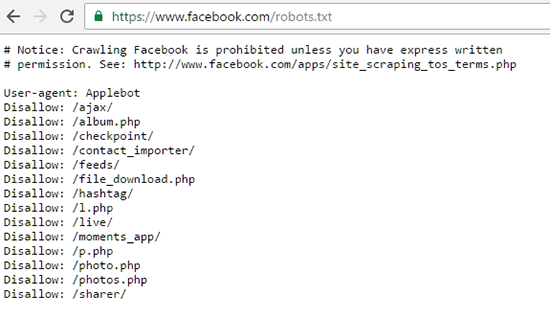
We have seen that a new website is a combination of various pages which can be a blog page, about us page, and various other pages. However, this is simple for us to navigate and I am talking about humans. This is definitely not easy to navigate for robots and for this reason, there was the need of robots.txt file and sitemaps. Basically, you are telling the robots in a robots.txt file that which page is located where on your website and which sites are needed to be indexed and not indexed.
However, the problem is that there are times when our robots.txt files are also indexed. Generally, there is no need to index the robots.txt file for any website as they are not useful for anyone to see. But the problem still occurs and we then need to de-index the file if needed or people just keep it as it is. While keeping it as it is not an issue, it is better to not index the robots.txt file in first place. So we now have advice from Google’s John Mueller on how to avoid indexing the robots.txt file for any website. He said that x-robots-tag HTTP header can be used to block indexing of robots.txt or sitemap files.
However, he also had some bad news for websites which had their robots.txt files indexed as he mentioned that “if your robots.txt or sitemap file is ranking for normal queries (not site:), that’s usually a sign that your site is really bad off and should be improved instead”. Google’s John Mueller revealed this when fellow Googler Gary Illyes revealed that there is no way to stop robots.txt file from indexing just like you would index normal URLs for your website. The key part about the statement from John is that if the robots.txt file is indexing, there is a problem which needs to be fixed.








OpenAI CEO says being polite to ChatGPT costs ‘tens of millions of dollars’

Microsoft researchers claim to have developed an AI that runs on CPUs

Samsung pushes One UI 7 update for Galaxy S23 series to May 2025: Report

OpenAI reportedly developing a social media platform to rival X and Meta
OpenAI to retire GPT-4 model and replace it with GPT-4o from ChatGPT by April 30

Google lays off hundreds in Platforms and Devices unit as part of restructuring efforts: Report

AI Overviews in Google Search ruining publishers’ website traffic: Bloomberg
-

 Domains5 years ago
Domains5 years ago8 best domain flipping platforms
-

 Business5 years ago
Business5 years ago8 Best Digital Marketing Books to Read in 2020
-

 How To's6 years ago
How To's6 years agoHow to register for Amazon Affiliate program
-
 How To's6 years ago
How To's6 years agoHow to submit your website’s sitemap to Google Search Console
-

 Domains4 years ago
Domains4 years agoNew 18 end user domain name sales have taken place
-

 Business5 years ago
Business5 years agoBest Work From Home Business Ideas
-

 How To's5 years ago
How To's5 years ago3 Best Strategies to Increase Your Profits With Google Ads
-

 Domains4 years ago
Domains4 years agoCrypto companies continue their venture to buy domains