News
SEO fixes the issue of crawled currently not indexed

A technical SEO has recently published a case study on how he has solved problems regarding crawled currently not indexed. However, the solution he has found may not be universal to others who are also experiencing this problem. However, his method of identifying this problem and solving it offers a much useful walk-through.
A really weird thing happened to his site while indexing. However, his solution was quite straightforward, and that makes sense. There are many anecdotal reports regarding the Crawled Currently Not Indexed problem on Facebook, Twitter, and in the Office-hours hangout of John Mueller.
During a recent Office-hours hangout, someone asked why GSC was showing crawled currently not indexed, but after clicking through, they turned out to be indexed. John Mueller has answered it as a lag within the reports. During another Office-hours hangout, John Mueller has pointed out that it is normal for a site to have many pages without indexing.
Adam Gent has discovered a completely different problem that appeared as an algorithm issue at Google. There was simply nothing wrong with the site itself. The problem was with the indexing of Google.
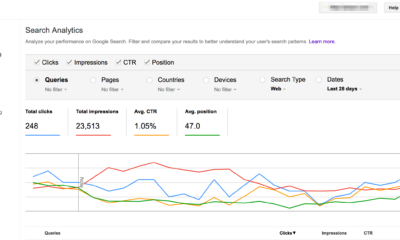
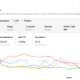
Adam has reviewed the GSC Index Coverage report. He discovered that Google was performing its crawl and indexing his feeds in the form of HTML pages. Also, he took up random words from such pages and opted for a site: search.
To make the matter even more difficult, Google has also canonicalized the content on the RSS feed over an actual web page. It is now accounting for why the real web pages have crawled but not indexed.
One odd thing about this case is, as you look at the feed page, it appears more like a web page and not how an XML file should render.
According to him, the page was not looking like a normal RSS feed; rather, it was more like an HTML page.
Even though the underlying code is XML, and that is not how most of the feeds will look normal. Well, the question that will normally come up is whether that could have played a role in why Google will opt to canonicalize that feed or not.
It is very hard enough to understand how this can happen. Since there are many signals like internal lining that can cause Google to favor canonical HTML pages.

When HOAs Become Hostage Regimes: The Perils of Self-Dealing and the Northwood Estates Litigation

The Data Is the Model: Jose M. Plehn’s Vision for Verifiable AI and Civil Society

95.3% of all ChatGPT users still depend on Google for their answers: Report
Spotify finally launches support for lossless streaming for Premium subscribers

Apple announces its latest iPhone, AirPods & Watch; iPhone 17 Air steals the show

OpenAI says it is building an AI-powered jobs platform; to rival LinkedIn

Samsung Galaxy S26 Edge leaked renders show copy of iPhone 17 design
-

 Domains6 years ago
Domains6 years ago8 best domain flipping platforms
-

 Business6 years ago
Business6 years ago8 Best Digital Marketing Books to Read in 2020
-

 How To's6 years ago
How To's6 years agoHow to register for Amazon Affiliate program
-
 How To's6 years ago
How To's6 years agoHow to submit your website’s sitemap to Google Search Console
-

 Domains5 years ago
Domains5 years agoNew 18 end user domain name sales have taken place
-

 Business6 years ago
Business6 years agoBest Work From Home Business Ideas
-

 How To's6 years ago
How To's6 years ago3 Best Strategies to Increase Your Profits With Google Ads
-

 Domains5 years ago
Domains5 years agoCrypto companies continue their venture to buy domains